
« Oracle HowTo:如何进行数据块转储及RDBA的转换 | Blog首页 | 字符集问题的初步探讨(一)-字符集的基本知识 »
字符集问题的初步探讨(二)-数据库的字符集

链接:https://www.eygle.com/archives/2004/09/nls_character_set_02.html
2. 数据库的字符集
在创建数据库时,我们可以指定字符集(CHARACTER SET)和国家字符集(NATIONAL CHARACTER SET)。
字符集用来存储:
CHAR, VARCHAR2, CLOB, LONG等类型数据
用来标示诸如表名、列名以及PL/SQL变量等
SQL和PL/SQL程序单元等
国家字符集用以存储:
NCHAR, NVARCHAR2, NCLOB等类型数据
这些设置在数据库创建时指定,我们可以看一下数据库的创建脚本:
|
connect SYS/change_on_install as SYSDBA |
以上用粗体显示的就是对我们至关重要的字符集设置。
在创建数据库的过程中,在以下界面选择你的字符集,对于简体中文平台,缺省的字符集是:ZHS16GBK
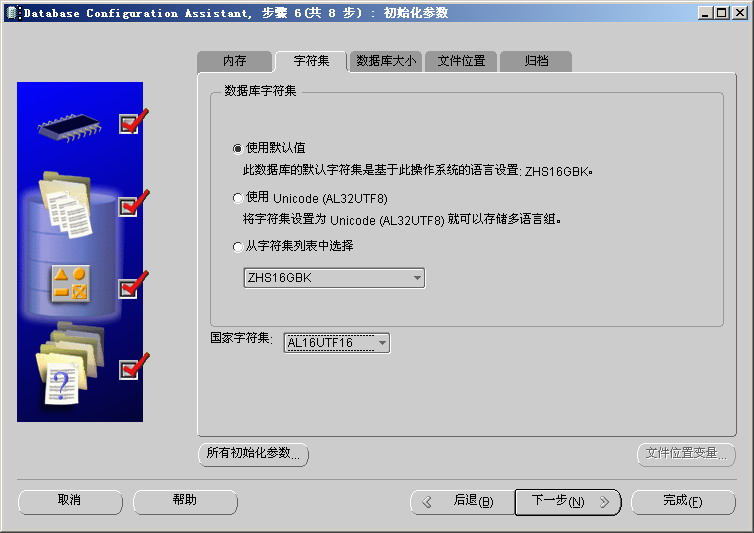
一旦你的字符集选定了,数据库中能够存储的字符就受到了限制,所以你选择的字符集的应该可以容纳所有你将用到字符。
常见的中文字符集有:
|
ZHS16CGB231280 CGB2312-80 16-bit Simplified Chinese MB, ASCII |
其中GB2312码是中华人民共和国国家汉字信息交换用编码,全称《信息交换用汉字编码字符集--基本集》,由国家标准总局发布,
1981年5月1日实施,通行于大陆。新加坡等地也使用此编码。
GBK编码是1995年12月颁布的指导性规范。
GBK与国家标准 GB 2312-80 信息处理交换码所对应的、事实上的内码标准兼容;同时,在字汇一级支持 ISO/IEC 10646-1 和
GB 13000-1 的全部中日韩 (CJK) 汉字(20902字)。包含了更多的编码。
但是我们说,ZHS16GBK 并非是ZHS16CGB231280的严格超集(虽然后者的汉字在前者中都存在,但是同样的编码在不同两个
字符集中可能表达不同的汉字),所以在做数据库字符转换时仍然需要特别注意。
Oracle的字符集命名遵循以下命名规则:
|
<Language><bit size><encoding> |
需要说明的是,有些字符集命名违背了这个规范,Oracle8/Oralce8i中的UTF-8是第一个打破这个命名规范的字符集。
我们可以看到一类字符集以 AL开头,如:
AL16UTF16
其中 AL代表 ALL,指适用于所有语言(All Languages),按照这个标准当年UTF-8本应被命名为AL24UTF8。
历史上的今天...
>> 2018-09-11文章:
>> 2009-09-11文章:
>> 2007-09-11文章:
>> 2006-09-11文章:
>> 2005-09-11文章:
By eygle on 2004-09-11 12:04 | Comments (0) | Special | 44 |